Feature transformation
Think of it as translating a story from one language to another depending on the audience. It deals with reshaping or molding the data to better highlight patterns and relationships, by applying mathematical or statistical operations to the data to create new features or modify existing ones.
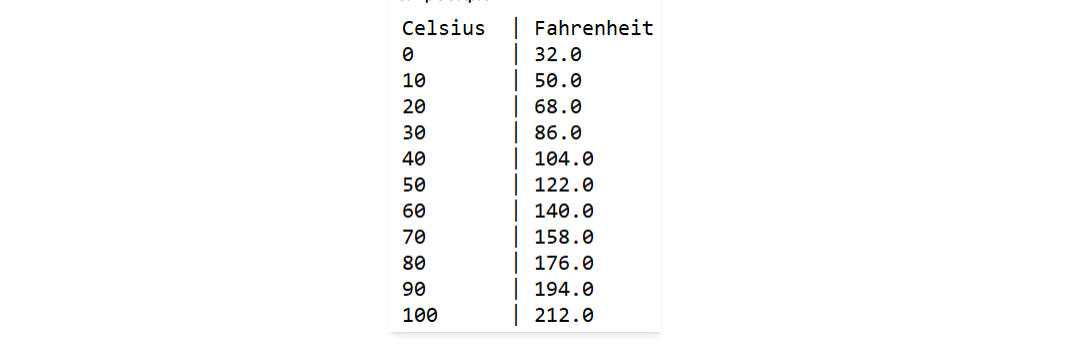
For example, imagine we have a dataset of temperatures in Celsius (°C), and we want to understand it in Fahrenheit (°F). Feature transformation can help us convert all the temperatures to Fahrenheit, making it easier for us to relate to and compare.
Feature transformation techniques
There are many different techniques for feature transformation, and the each technique has its purpose and can be applied depending on the characteristics of the data and the specific analysis goals. In this lesson, we'll look at 2 techniques used for transformation - scaling and binning.
1. Scaling
Feature scaling involves making sure that all our numeric features in the data have a similar range of values. This includes rescaling numerical features to a common range, such as 0 to 1 or -1 to 1. It ensures that all features have a similar influence on the analysis and prevents any one feature from dominating (or bullying 😁) the others.
Let's look at an example of scaling features in a dataset. Imagine we have a dataset containing both numeric and non-numeric features, we can scale the numeric features using the code snippet below.
We used Min-Max (or Normalization) scaling technique to scale the numeric features (Age, Height, Weight, Income, and Experience), but then we modified the scaled values to ensure they are positive, by adding the absolute minimum value of the scaled data. Other scaling techniques includes
- Standardization (or Zero Score)
- Max scaling
- Robust Scaling
- Power
- Box-Cox
- Quantile
- Rank
- Unit Vector Scaling
Check your understanding: Scaling
You are working with a dataset that contains information about different houses for sale. Here's a simplified version of the dataset:
House ID: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Square Feet: [1200, 1500, 1800, 900, 2200, 1000, 1600, 1300, 1100, 1700]
Bedrooms: [2, 3, 4, 2, 4, 2, 3, 2, 2, 3]
Bathrooms: [1, 2, 2, 1, 3, 1, 2, 1, 1, 2]
Year Built: [1995, 2000, 1985, 2005, 2010, 1998, 2002, 1990, 2008, 2015]
Price ($): [150000, 200000, 230000, 120000, 280000, 140000, 210000, 180000, 160000, 220000]
Task: Perform min-max scaling on the Square Feet feature to bring it into the range [0, 1].
2. Binning
Binning is the process of dividing a continuous feature (e.g., age) into discrete intervals or bins. It's like creating age groups to make it easier to understand and analyze the data. For example, let's say we have a dataset of customer ages, and we want to bin the ages into 5 bins, the we have
- 0-18 years old
- 19-30 years old
- 31-45 years old
- 46-60 years old
- 61+ years old
We can then assign each customer to a bin based on their age. This would allow us to use the binned age as a categorical feature, rather than wide range of continuos values. Binning helps simplify the data and make it easier to interpret and analyze, thereby allowing us to summarize the data in a meaningful way and uncover insights that may not be apparent when looking at individual values.
Let's use another example to demonstrate binning. Suppose we have a dataset containing information about students' test scores, and we want to bin their scores into different performance categories, such as Low, Medium, and High. Here's a sample DataFrame with six features: Student_ID, Math_Score, Science_Score, English_Score, History_Score, and Total_Score:
In this example, we used the pandas cut() function to bin the Math_Score column into three categories: "Low" (scores below 70), "Medium" (scores between 70 and 80), and "High" (scores above 80). The new column "Math_Category" has been added to the DataFrame to store the respective category for each student's math score.
Different binning techniques can be used depending on the data and analysis goals. Here are some common binning techniques:
- Equal Width: Dividing the data into bins of equal width. For example, dividing age into bins like
0-10 years,11-20 years, etc. - Equal Frequency: Dividing the data into bins with an equal number of data points. This can help handle
skeweddata. - Custom: Defining specific bins based on domain knowledge or specific requirements.
Check your understanding: Binning
You are working with a dataset that contains information about different houses for sale. Here's a simplified version of the dataset:
House ID: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Square Feet: [1200, 1500, 1800, 900, 2200, 1000, 1600, 1300, 1100, 1700]
Bedrooms: [2, 3, 4, 2, 4, 2, 3, 2, 2, 3]
Bathrooms: [1, 2, 2, 1, 3, 1, 2, 1, 1, 2]
Year Built: [1995, 2000, 1985, 2005, 2010, 1998, 2002, 1990, 2008, 2015]
Price ($): [150000, 200000, 230000, 120000, 280000, 140000, 210000, 180000, 160000, 220000]
Task:
Apply binning on the Year Built feature to categorize houses into decades (e.g., 1980s, 1990s, etc.)
➡️ In the next section, we'll be looking at
Feature encoding🎯.