Overfitting and underfitting
In previous lessons, we've seen how we can build and evaluate an ML model to be sure of its performance. However, what happens if our ML model performs well during evaluation but fails to generalize (or perform) to new, unseen data? Sometimes, our model can either just memorize the training data or doesn't learn any pattern from it, leading to irregular balance and poor performance.
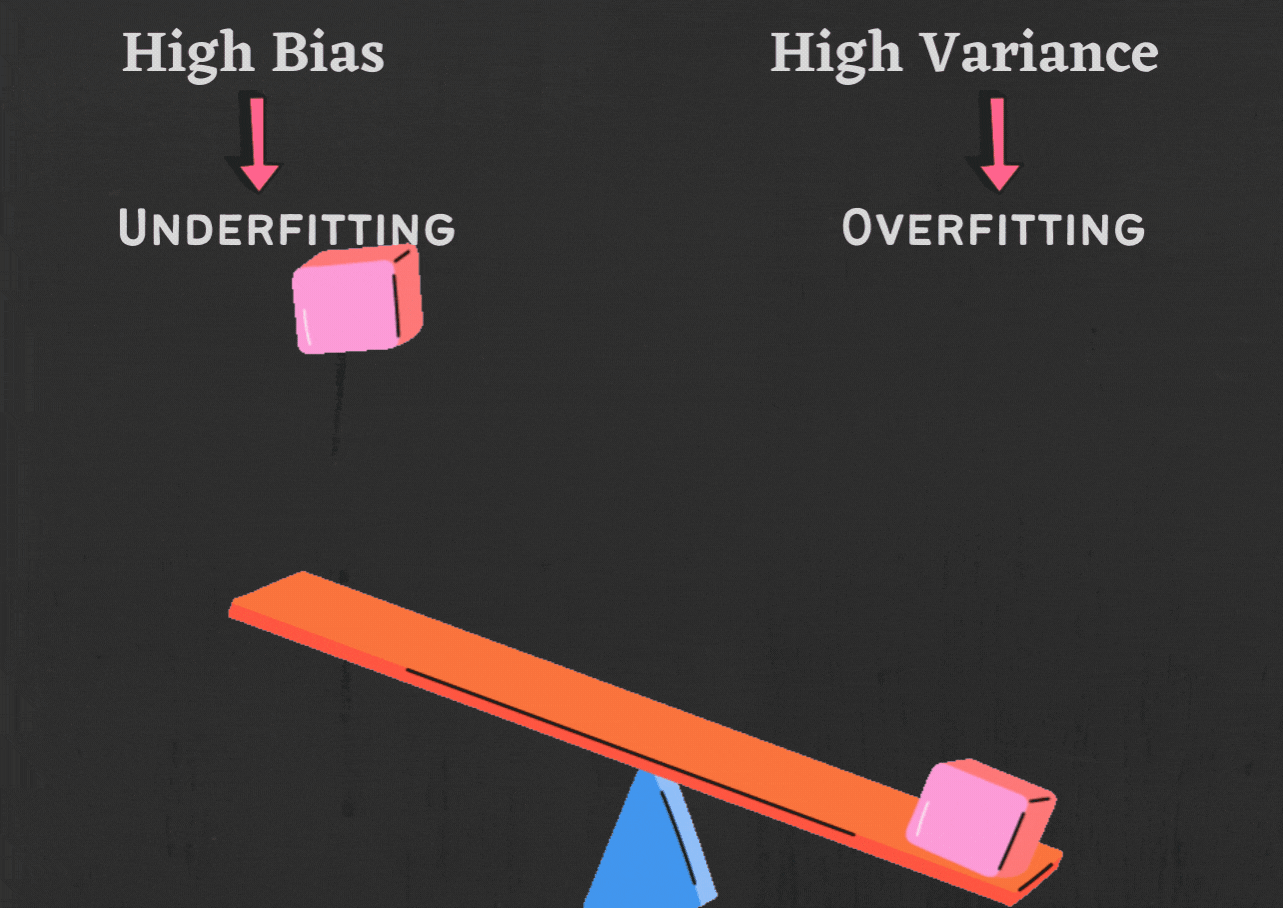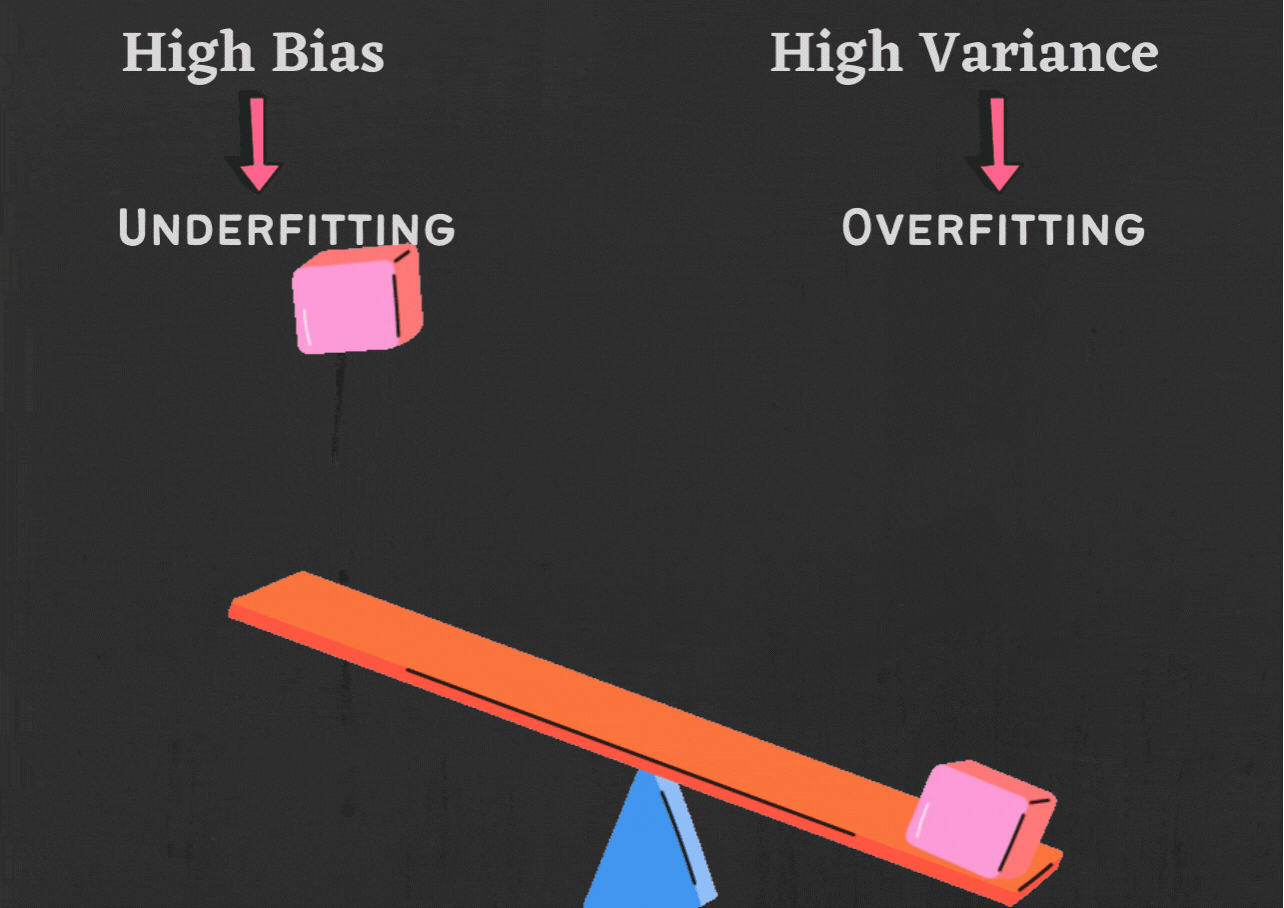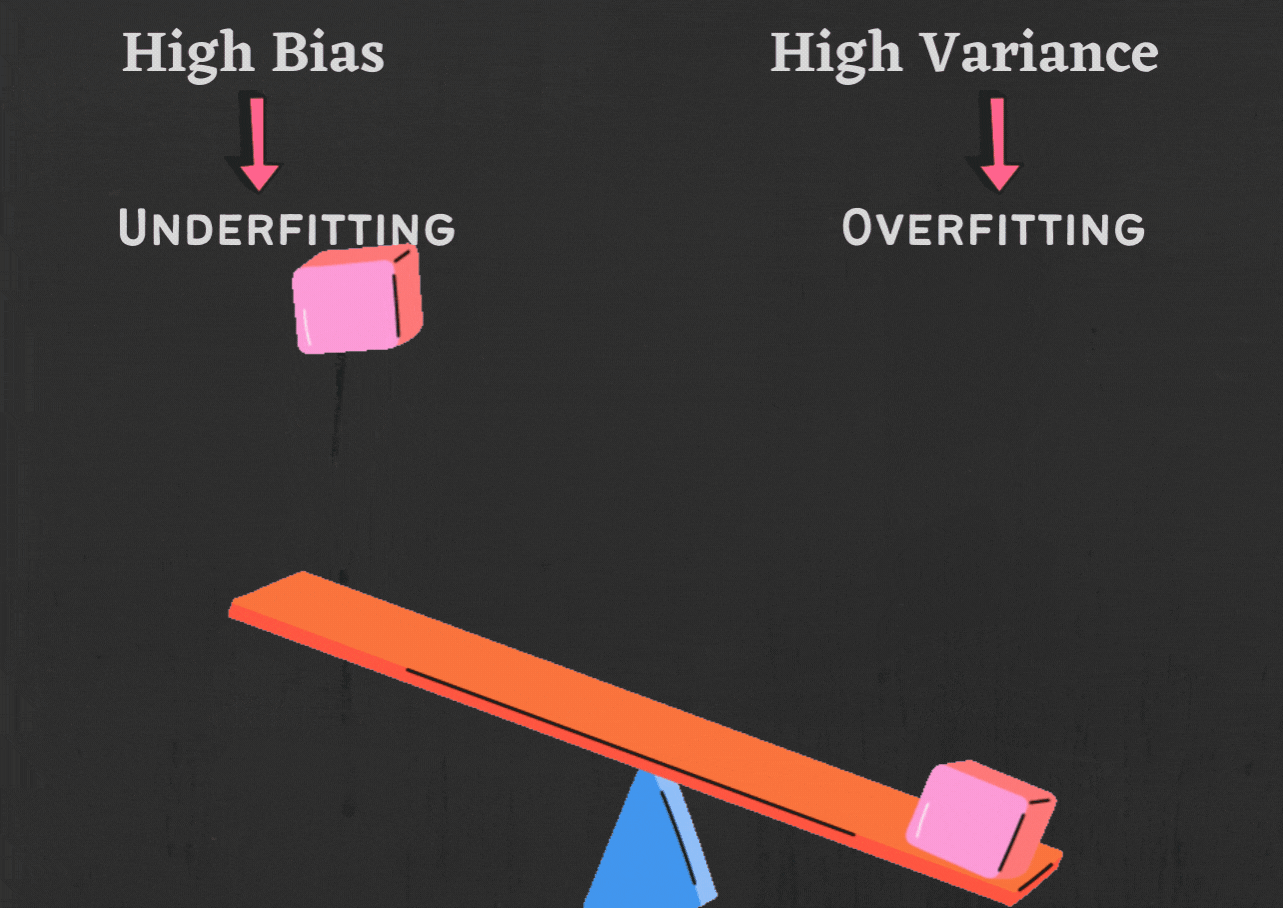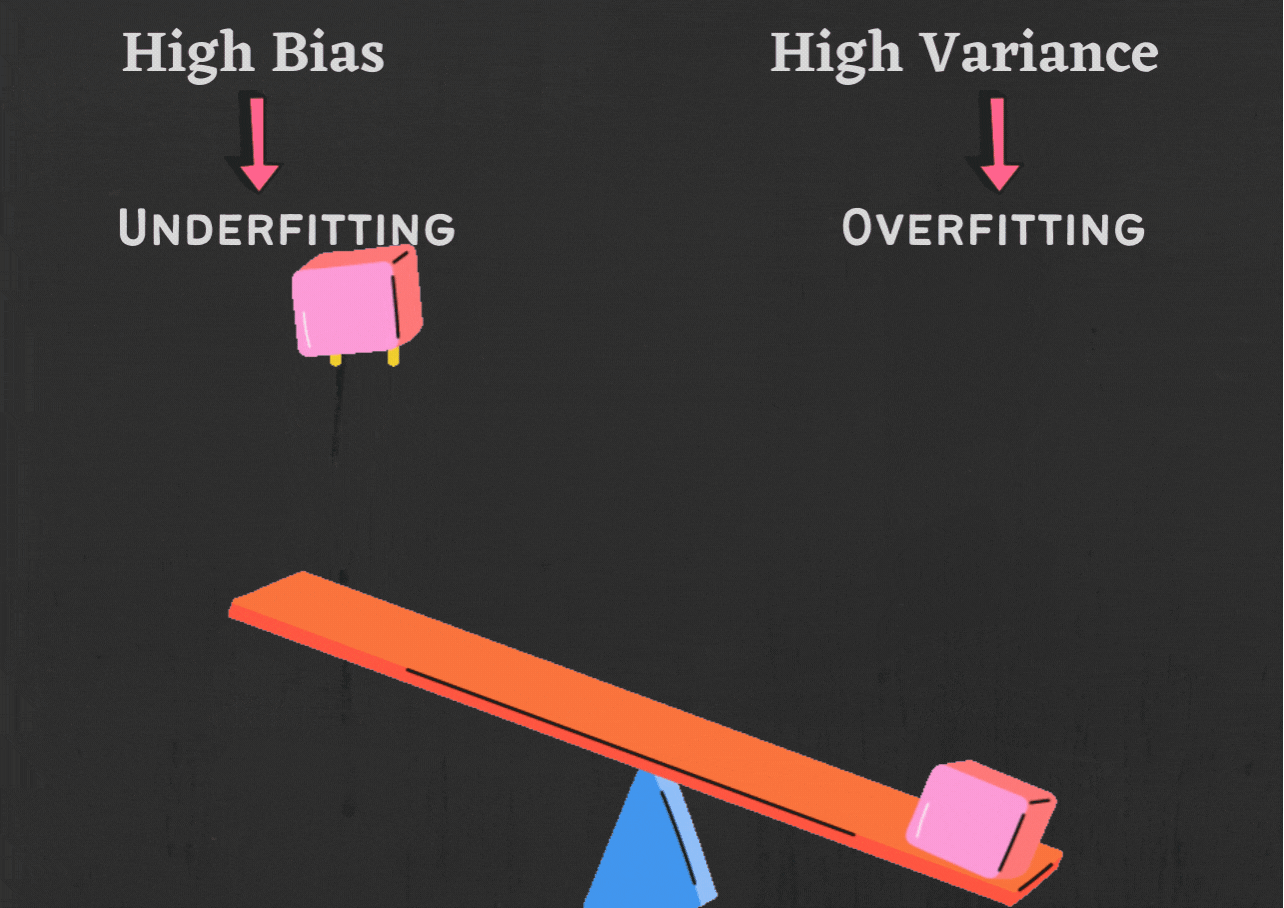
Overfitting
Imagine a student is preparing for a math exam. They have a textbook with several example problems and solutions. The student spends hours memorizing the solutions to those specific problems, hoping to see similar questions on the exam.
When the exam day arrives, they encounter a set of questions that are slightly different from the ones they memorized. Despite their efforts to recall the exact solutions they memorized, they struggle to apply them to the new problems. As a result, they don't perform as well as they expected, even though they knew the answers to the problems they memorized. This is an example of overfitting.
Overfitting occurs when a model becomes too complex and captures noise or random fluctuations in the training data rather than learning the underlying patterns. Some common causes of overfitting include:
- Insufficient training data: When the training dataset is small, the model may not capture the full complexity of the underlying relationships, leading to overfitting.
- Too many features: If a model has too many features, it can start to memorize the training data instead of learning the underlying patterns. This can lead to overfitting.
- Data Imbalance: In classification tasks, when one class dominates the dataset and is significantly more frequent than the others, the model may favor the dominant class and struggle to correctly predict the less frequent classes.
- High variance: High variance means that the model is sensitive to small changes in the training data. This can lead to overfitting, as the model will learn the noise in the training data instead of the underlying patterns.
Implementing overfitting
To demonstrate overfitting due to a small data sample and imbalanced data, let's use a simple example of classifying flowers into two categories: rose and tulip. We'll create a synthetic dataset with a small number of samples and an imbalance between the two classes. Play around with the new test data new_data and observe the changes in the model predictions.
In the code snippet, we have only 12 samples, with 10 samples of rose and 2 samples of tulip. This dataset is small and imbalanced, as rose has more data than tulip. When we train the Decision Tree Classifier on this dataset, it may create a very complex decision boundary to perfectly fit the small number of training samples.
As a result, the model may perform very well on the training data (high training accuracy) but poorly on new, unseen data (low testing accuracy). In real-world scenarios, overfitting due to a small dataset or imbalanced classes can lead to poor generalization and unreliable model performance.
Underfitting
Using same example of a student preparing for a math exam, suppose this time the student is not putting enough effort into studying and is only glancing briefly at the textbook without really understanding the concepts.
When the exam day arrives, the student feels unprepared and struggles to solve even the simplest problems. They might guess the answers or leave many questions unanswered because they didn't learn the necessary concepts in-depth. As a result, their performance is much lower than expected, even on straightforward questions.
Underfitting can be a major problem in machine learning. There are a few things that can cause this, including:- Too simple model: If a model is too simple, it may not be able to learn the complex patterns in the data. This can lead to underfitting.
- Not enough features: If a model does not have enough features, it may not be able to learn enough about the data to make accurate predictions.
- Not enough training data: If a model is not trained on enough data, it may not be able to learn the underlying patterns in the data and may underfit the data.
➡️ Next, we'll look at
Cross validation... 🎯