Text Preprocessing
Text preprocessing in NLP is like getting the text ready for the computer to understand. It's like tidying up a messy room before guests come over. You remove any extra stuff that doesn't matter, like soccer ball, empty bottles or old newspapers.

Similarly, in text, we might get rid of things like punctuation marks and extra words that don't add much meaning. When computers read and understand human language (like articles, reviews, or tweets), they also need to clean up and organize the words.
Text preprocessing techniques
By cleaning up the texts, the computer can understand it better and do cool things like figuring out if people are happy or sad in reviews, sort news articles into categories, or even translate languages 😍. Now, let's discuss some techniques used in text preprocessing.
1. Casing
Casing refers to the use of uppercase (capital) or lowercase letters in text. It might not seem like a big deal, but casing can have a significant impact on how computers understand and process language.
In general, Kibo and kibo are generally considered to be the same word. However, in NLP, these could be treated as different words if casing is not handled properly. Let's look at an example of why casing is important.
-
Lowercasing: Many NLP tasks, like text classification or sentiment analysis, doesn't need to distinguish between
Kiboandkibo. By converting all text to lowercase, we treat them as the same word. This helps improve the accuracy and consistency of NLP models.- Example: "I want to eat an Apple" → "i want to eat an apple"
-
Maintaining Casing: In some cases, the casing can carry important information. For instance, if you're analyzing tweets, uppercase words might indicate emphasis or shouting. To retain this information, you might choose not to lowercase the text.
- Example: "AMAZING DEAL! Get 50% off today!" - preserving casing to capture emphasis.
Now let's look at code examples of converting a text to lowercase using Spacy.
2. Tokenization
Tokens are essentially the individual words, phrases, or symbols that make up a text. Tokenization is a fundamental step in many natural language processing tasks, as it lays the foundation for further analysis, processing, and understanding of textual data.
For example, let's consider the sentence: I am studying at Kibo. Tokenization of this sentence would result in the following tokens:
"I" "am" "studying" "at" "Kibo" "."
Programmatically, we can tokenize a sentence or document with Spacy using the following code snipppet:
Each of these tokens represents a discrete unit of meaning, and breaking down the text into tokens enables computers to process and analyze text more effectively.
3. Stopwords and punctuation removal
Stopwords are common terms that doesn't contribute much to the meaning of a sentence. For example, is, and, the are stopwords in the English language. Both stopwords and punctions needs to be removed to focus on the more important words in the text.
In the code snippet above, we loaded the English NLP model from Spacy. Then, we define a sample text and process it using the nlp object. We iterate through the processed tokens and use the is_stopand is_punct attribute to check if a token is a stopword or punctuation. If it's not, we add it to the list of processed text.
4. Whitespace trimming
Thiclude removing unnecessary spaces, tabs, and newline characters from a text. It can be useful for cleaning and normalizing text data in NLP tasks to ensure consistency and improve the accuracy of NLP models.
Here's an example of how to perform whitespace trimming using NLTK:
This code snippet will tokenize the input text using NLTK and then join the tokens back together to create a new text without the extra spaces.
5. Stemming and Lemmatization
Stemming involves reducing words to their base or root form. It removes suffixes from words to get to the core meaning of a word. For example, the stem of the words interchanger and interchanging would be interchang. This technique reduces words to their root forms to consolidate variations of the same word.
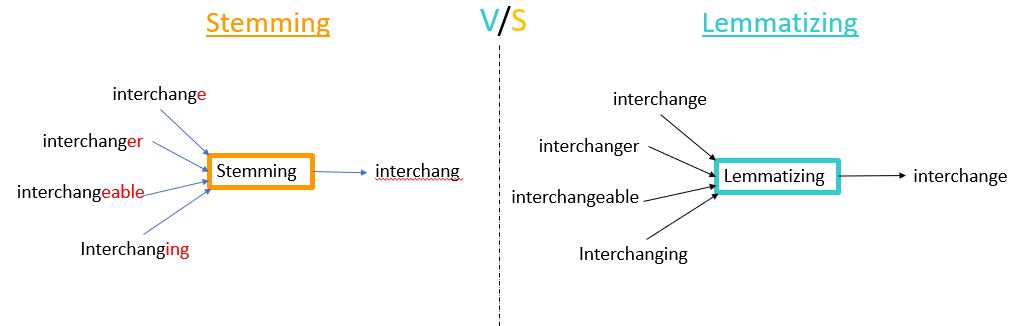
Lemmatization also reduces words to their base form, However it does so in a more intelligent way by considering the context and part of speech of the word, so that the resulting base form (called a lemma) is a valid word that makes sense. For example, the stem of the words interchanger and interchanging would be interchange.
Stemming might produce words that are not actual words, while lemmatization aims to produce meaningful and valid words.
👩🏾🎨 Practice: Text preprocessing... 🎯
Imagine you have a dataset of customer reviews from an online store. Each row in the dataset represents a customer review. Here's a snippet of the dataset:
Dataset: Customer Reviews
| Review_ID | Customer_Name | Review_Text |
|---|---|---|
| 1 | John | Great product! I love it. |
| 2 | Emily | The product was okay, not very impressed. |
| 3 | Michael | This is the worst thing I've ever bought. |
| 4 | Sarah | Product is good. |
| 5 | David | I have mixed feelings about this purchase. |
Questions:
-
Casing: Convert the text in the "Review_Text" column to lowercase.
-
Tokenization: Tokenize the "Review_Text" column to break it into individual words or tokens.
-
Stopword Removal: Remove common stopwords (e.g., "the," "is," "I") from the tokenized text in the "Review_Text" column.
-
Stemming: Apply stemming to the tokenized text in the "Review_Text" column. Use the Porter Stemmer algorithm.
-
Lemmatization: Apply lemmatization to the tokenized text in the "Review_Text" column.
-
What is the purpose of converting text to lowercase in text preprocessing?
- A. To remove stopwords
- B. To make the text more readable
- C. To standardize text for analysis
- D. To perform stemming
-
What is the result of tokenizing the sentence "Great product! I love it."?
- A. ["Great", "product!", "I", "love", "it."]
- B. ["great", "product", "i", "love", "it"]
- C. ["Great product!", "I love it."]
- D. ["great", "product", "i", "love", "it."]
➡️ Next, we'll look at
Text representations... 🎯.